Yapay Zeka Dijital Kütüphaneleri ve Kültürel Hafızayı Nasıl Değiştiriyor?


Bir kütüphane düşünün.
Raflarda sessizce bekleyen kitaplar yok sadece.
Tozlu arşiv kutuları, eski gazeteler, unutulmuş fotoğraflar ya da yıllar önce dijitalleştirilmiş belgeler de artık eskisi gibi durmuyor.
Çünkü bugün kütüphaneler ve arşivler yalnızca geçmişi saklayan yerler değil.
Yapay zekanın öğrendiği, yorumladığı, seslendirdiği, sınıflandırdığı ve bazen de yeniden keşfettiği devasa bilgi ekosistemlerine dönüşüyor.
Bir zamanlar “kitapların dijital ortama aktarılması” başlı başına büyük bir devrimdi. Bugün ise mesele artık kitabı taramak ya da PDF’e çevirmek değil. Asıl soru şu:
Bu kadar büyük kültürel mirası yapay zeka ile nasıl daha erişilebilir, daha anlamlı ve daha güvenilir hale getirebiliriz?
İşte dijital kütüphanelerin, açık erişim arşivlerinin ve kültürel miras kurumlarının bugün uğraştığı en büyük mesele tam olarak bu.
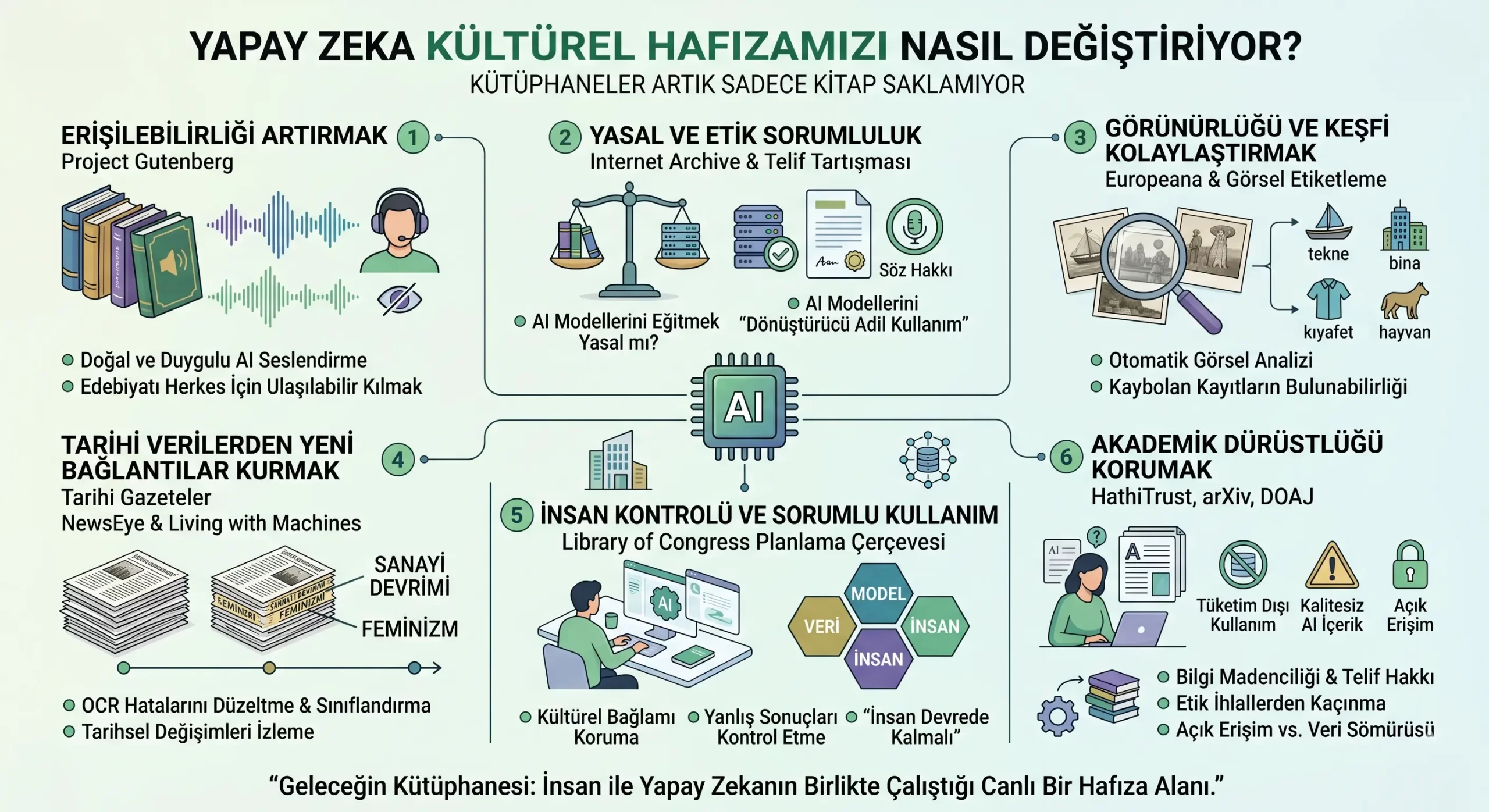
Kitaplar Artık Sadece Okunmuyor, Dinleniyor ve Yeniden Keşfediliyor
Dünyanın en eski dijital kütüphanelerinden biri olan Project Gutenberg, yıllardır telif hakkı süresi dolmuş klasik eserleri ücretsiz olarak okurlarla buluşturuyor. Ancak son dönemde bu misyonu bir adım ileri taşıdı.
Yeni Nesil Seslendirme Teknolojileri
Microsoft ve MIT ile yapılan çalışmalar sayesinde binlerce klasik kitap, yapay zeka destekli sesli kitaplara dönüştürüldü.
Bu ilk bakışta basit bir “metni sese çevirme” işi gibi görünebilir. Ama aslında bundan çok daha fazlası var. Eski tip bilgisayar seslerini hatırlayın: mekanik, soğuk, duygusuz. Yeni nesil yapay zeka seslendirmelerinde ise metnin ritmi, duygusu, karakter yapısı ve anlatım tonu daha doğal biçimde işlenebiliyor.
Örneğin bir Shakespeare metni seslendirilirken sistem farklı karakterler için farklı ses profilleri oluşturabiliyor. Böylece metin sadece okunmuş olmuyor; bir bakıma yeniden sahneleniyor.
Bu özellikle görme engelliler, disleksi gibi okuma güçlüğü yaşayanlar, yeni dil öğrenenler ya da kitaplara dinleyerek ulaşmayı tercih edenler için çok önemli. Çünkü yapay zeka burada sadece teknolojik bir yenilik sunmuyor; bilgiye erişimdeki engelleri azaltıyor.
Yani mesele yalnızca “kitapları seslendirmek” değil.
Mesele, edebiyatı daha fazla insan için ulaşılabilir hale getirmek.
Internet Archive: Dijital Hafızanın Kalbi ve Büyük Telif Tartışması
Internet Archive ise bambaşka bir noktada duruyor.
Onu çoğu kişi eski web sitelerini bulduğumuz Wayback Machine ile tanıyor. Ama Internet Archive bundan çok daha büyük bir dijital hafıza alanı. Kitaplar, filmler, ses kayıtları, web sayfaları, eğitim materyalleri ve daha pek çok içerik burada korunuyor.
Yapay zeka çağında Internet Archive’in önemi daha da arttı. Çünkü yapay zeka sistemleri öğrenmek için veriye ihtiyaç duyuyor. Kitaplar, makaleler, arşivler ve metin koleksiyonları bu öğrenme sürecinin temel kaynakları arasında yer alıyor.
Yapay Zeka Eğitiminde “Adil Kullanım” Sınırı
Burada büyük bir soru doğuyor: Bir yapay zeka modelini eğitmek için telifli kitaplardan yararlanmak yasal mı?
Bu soru son yılların en hararetli tartışmalarından biri. 2025’te ABD’de görülen önemli bir davada mahkeme, fiziksel olarak satın alınan kitapların dijitalleştirilip yapay zeka eğitimi için kullanılmasını bazı koşullarda “dönüştürücü adil kullanım” kapsamında değerlendirdi.
Bu karar, kütüphaneler ve yapay zeka şirketleri açısından büyük bir dönüm noktası olarak görülüyor. Çünkü kitapların yalnızca okunacak nesneler değil, aynı zamanda algoritmalar tarafından analiz edilecek veri kaynakları haline geldiğini gösteriyor.
Ama bu aynı zamanda şu soruyu da beraberinde getiriyor: İnsanlığın ortak kültürel mirası, büyük teknoloji şirketlerinin eğitim verisine dönüşürken kim ne kadar söz sahibi olacak?
Bu soru henüz tam olarak cevaplanmış değil.
Yapay Zeka Arşivlerde Ne İşe Yarıyor?
Yapay zeka denince çoğu kişinin aklına sohbet botları, görsel üreticiler ya da otomatik metin yazan sistemler geliyor. Oysa kütüphanelerde ve arşivlerde yapay zekanın çok daha sessiz ama çok etkili görevleri var.
Mesela milyonlarca görselin bulunduğu bir kültürel miras arşivini düşünün. Tarihi tablolar, fotoğraflar, el yazmaları, afişler, haritalar, gazete kupürleri… Bunların her birini insan eliyle tek tek etiketlemek neredeyse imkansız.
Europeana ve Bilgisayarlı Görü Sistemleri
Europeana gibi Avrupa’nın büyük dijital kültürel miras platformları bu sorunu yapay zeka ile çözmeye çalışıyor. Bilgisayarlı görü sistemleri, görsellerin içinde yer alan nesneleri otomatik olarak tanıyabiliyor.
Bir arşiv görselinde tekne, bina, böcek, insan figürü, kıyafet, hayvan ya da belirli bir nesne varsa sistem bunları algılayıp görselin üst verisine ekleyebiliyor. Böylece daha önce bulunması çok zor olan kayıtlar, arama motorlarında görünür hale geliyor.
Bu kulağa teknik gelebilir ama sonucu çok basit: Eskiden arşivde kaybolan bir görsel, artık doğru anahtar kelimeyle bulunabilir hale geliyor.
Eski Gazeteler, Yeni Sorular
Yapay zekanın kültürel mirastaki en etkileyici kullanım alanlarından biri de tarihi gazeteler.
-
ve 20. yüzyıla ait milyonlarca gazete sayfasını düşünün. İçlerinde haberler, ilanlar, karikatürler, fotoğraflar, siyasi tartışmalar, toplumsal değişimler ve gündelik hayatın izleri var. Bir araştırmacının tüm bu gazeteleri tek tek okuması mümkün değil. Ama yapay zeka bu devasa metin yığınları içinde desenler bulabiliyor.
Gallica, NewsEye ve Living with Machines Projeleri
Fransa Millî Kütüphanesi’nin Gallica platformu ve NewsEye projesi bu açıdan çok değerli örnekler sunuyor. Yapay zeka, eski gazetelerdeki OCR hatalarını düzeltebiliyor, metinleri sınıflandırabiliyor, temaları gruplayabiliyor ve araştırmacıların belirli dönemlerde belirli kavramların nasıl kullanıldığını takip etmesine yardımcı oluyor.
Örneğin 1850 ile 1950 yılları arasında “kadın”, “feminizm”, “işçi”, “makine”, “sanayi” gibi kavramların gazetelerde nasıl yer aldığını araştırmak artık çok daha mümkün.
Benzer şekilde British Library’nin “Living with Machines” projesi, Sanayi Devrimi’nin toplum üzerindeki etkilerini büyük gazete arşivleri üzerinden inceleyerek tarih araştırmalarına yepyeni bir yöntem kazandırıyor.
Yani yapay zeka burada tarihin yerini almıyor.
Ama tarihçilerin daha önce göremediği bağlantıları görmesine yardımcı oluyor.
Kongre Kütüphanesi’nin Mesajı Net: İnsan Devrede Kalmalı
Amerika Birleşik Devletleri Kongre Kütüphanesi, yapay zekaya oldukça dikkatli yaklaşan kurumlardan biri.
Onlara göre yapay zeka güçlü bir araç olabilir. Ama kültürel miras gibi hassas bir alanda kontrolsüz kullanılmamalı. Bu yüzden Library of Congress, yapay zeka projeleri için kapsamlı bir planlama çerçevesi oluşturdu.
Bu yaklaşımda üç unsur öne çıkıyor: Veri, model ve insan.
-
Veri hazır mı?
-
Model neyi nasıl öğrenecek?
-
Bu süreçten kim etkilenecek?
-
Yanlış sonuçlar nasıl kontrol edilecek?
-
Kültürel bağlam nasıl korunacak?
Bu soruların her biri önemli. Çünkü arşivler yalnızca veri yığınlarından oluşmaz. Her belgenin bir bağlamı, her görselin bir hikayesi, her kaydın temsil ettiği bir insan veya topluluk vardır.
Bu yüzden Kongre Kütüphanesi’nin yaklaşımı çok değerli bir ilkeye dayanıyor: Yapay zeka yardımcı olabilir, ama son söz insanda kalmalıdır.
Bu ilke özellikle kültürel miras alanında hayati öneme sahip. Çünkü algoritmalar hızlı olabilir ama her zaman doğru, adil ya da bağlama duyarlı olmayabilir.

Akademik Dünyada Yapay Zeka: Fırsat mı, Tehdit mi?
Açık erişim akademik platformları da yapay zekadan derinden etkileniyor. HathiTrust gibi büyük dijital kütüphaneler, milyonlarca kitabı araştırmacıların metin madenciliği yapabileceği şekilde kullanıma açıyor. Ama bunu yaparken telif hakkını ihlal etmemek için çok akıllı bir yöntem izliyorlar.
“Tüketim-Dışı Kullanım” Yaklaşımı
Araştırmacıya kitabın tam metnini vermek yerine, metinden çıkarılmış teknik veriler sunuyorlar. Mesela kelime sıklıkları, sözcük türleri, sayfa bazlı istatistikler gibi bilgiler paylaşılabiliyor. Böylece araştırmacı kitabı doğrudan okuyamıyor ama büyük koleksiyonlar üzerinde eğilim analizi yapabiliyor.
Bu yaklaşıma “tüketim-dışı kullanım” deniyor. Basitçe şöyle düşünebiliriz: Kitabı okumuyorsunuz, ama kitapların içindeki büyük örüntüleri analiz edebiliyorsunuz. Bu, telif hakkı ile bilimsel araştırma arasında oldukça dengeli bir çözüm sunuyor.
arXiv ve Bilgi Kirliliği Riski
Fakat akademik dünyada yapay zekanın yarattığı başka bir sorun daha var: Yapay zeka ile üretilen kalitesiz, kontrol edilmemiş ve bazen tamamen hatalı akademik metinler.
arXiv gibi ön baskı platformları bu sorunla ciddi biçimde karşı karşıya. Bazı kullanıcılar, yapay zekanın ürettiği metinleri yeterince okumadan, kontrol etmeden veya doğrulamadan sisteme yükleyebiliyor. Bu da bilimsel bilgi ekosisteminde büyük bir kirlilik yaratıyor.
arXiv bu nedenle oldukça sert politikalar geliştirdi. Yapay zekanın yardımcı araç olarak kullanılmasını tamamen yasaklamıyor. Ama yapay zeka tarafından üretilmiş hatalı, uydurma, doğrulanmamış veya açıkça kontrol edilmemiş içeriklerin akademik platformlara yüklenmesini ciddi bir etik ihlal olarak görüyor.
Bu çok önemli bir ayrım. Sorun yapay zekayı kullanmak değil. Sorun, yapay zekanın ürettiği şeyi düşünmeden ve sorumluluk almadan kullanmak.
Açık Erişim ve Veri Sömürüsü Arasındaki İnce Çizgi
DOAJ gibi açık erişim platformları da yapay zeka çağında yeni bir ikilem yaşıyor.
Açık erişim fikri çok değerli: Bilimsel bilgi herkesin erişimine açık olmalı. Makaleler yalnızca ödeme yapabilen kurumların ya da kişilerin ulaşabileceği kapalı alanlarda kalmamalı. Ancak yapay zeka çağında bu açıklık başka bir sorunu gündeme getiriyor. Çünkü büyük teknoloji şirketleri, açık erişimli akademik içerikleri yapay zeka modellerini eğitmek için devasa ölçekte tarayabiliyor.
Burada etik bir gerilim oluşuyor: Bir tarafta bilginin özgürce dolaşması var. Diğer tarafta ise kamusal veya akademik emekle üretilmiş içeriklerin, milyar dolarlık ticari sistemlerin eğitim verisine dönüşmesi var.
Türkiye’deki Açık Erişim Platformlarının Durumu
Özellikle Türkiye gibi açık erişimin güçlü olduğu ülkelerde bu konu daha da önemli hale geliyor. DergiPark ve TR Dizin gibi platformlar sayesinde binlerce akademik dergi açık erişimli olarak yayımlanıyor. Bu durum bilimsel görünürlük için büyük bir avantaj. Ama aynı zamanda bu içeriklerin yapay zeka şirketleri tarafından nasıl kullanıldığı sorusunu da gündeme getiriyor.
Açık bilgi güzel.
Ama açık bilginin adil kullanımı da en az onun kadar önemli.
Peki Bütün Bunlar Bize Ne Söylüyor?
Dijital kütüphaneler, arşivler ve açık erişim platformları artık sadece “geçmişi saklayan” yerler değil. Onlar, yapay zeka çağının en önemli veri kaynakları, etik tartışma alanları ve kültürel güvenlik merkezleri haline geliyor.
-
Project Gutenberg, klasik eserleri daha erişilebilir hale getiriyor.
-
Internet Archive, dijital hafızanın sınırlarını ve telif hukukunu yeniden tartışmaya açıyor.
-
Europeana, kültürel mirası yapay zeka ile daha görünür kılıyor.
-
Kongre Kütüphanesi, insan denetiminin vazgeçilmez olduğunu hatırlatıyor.
-
HathiTrust, telif hakkı ile araştırma arasında yeni yollar açıyor.
-
arXiv, akademik dürüstlüğü yapay zeka çağında korumaya çalışıyor.
-
DOAJ ise açık erişimin veri sömürüsüne dönüşmemesi için yeni etik sorular soruyor.
Bütün bu örneklerin ortak noktası şu: Yapay zeka, kültürel mirası daha erişilebilir hale getirebilir. Ama bunu yaparken insan aklını, etik sorumluluğu ve kamusal faydayı merkeze almak zorundayız.
Çünkü kütüphaneler yalnızca kitapların evi değildir.
Arşivler yalnızca eski belgelerin saklandığı yerler değildir.
Açık erişim platformları yalnızca akademik makale depoları değildir.
Bunların hepsi insanlığın ortak hafızasını taşır. Ve bugün bu hafıza, yapay zeka tarafından okunuyor, sınıflandırılıyor, seslendiriliyor, analiz ediliyor ve yeniden anlamlandırılıyor.
Asıl mesele şu: Bu dönüşümü yalnızca daha hızlı sistemler kurmak için mi kullanacağız, yoksa bilgiyi daha adil, daha erişilebilir ve daha insani hale getirmek için mi?
Geleceğin kütüphanesi belki de sessiz raflardan çok, insan ile yapay zekanın birlikte çalıştığı canlı bir hafıza alanı olacak. Ama o hafızanın gerçekten bize ait kalması için, teknolojiyi sadece akıllı değil; aynı zamanda sorumlu kullanmayı öğrenmemiz gerekiyor.
Yapay zeka ve dijital kütüphaneler
—
Yazarın diğer yazıları için tıklayınız.
The post Yapay Zeka Dijital Kütüphaneleri ve Kültürel Hafızayı Nasıl Değiştiriyor? first appeared on CRB Haber.
Bir yanıt yazın